Este artigo tem como objetivo falar o que é teste de software, apresentando a nomenclatura utilizada, como os conceitos de erro, defeito, falha, e a relação entre eles, bem como os conceitos de risco, qualidade, e suas classificações. Também será visto o porquê devemos fazer a prática de teste de software, quais sãos os princípios envolvidos, os fundamentos do processo de desde, e as questões psicológicas. Então vamos começar pelos três primeiros conceitos: um erro, ou também chamado de engano quando ocasionado por uma pessoa, gera um defeito em um sistema, defeito este que pode ser observado através de uma falha, que seria a manifestação visível e mensurável de um defeito.
Erros em sua grande maioria são cometidos por pessoas, e podem ocorrer por diversos fatores: seja através de uma pressão para atingir um prazo, alto nível de complexidade e organização de um sistema, bem como alterações de escopo e tecnologia do projeto, que acabam por pressionar as pessoas que estão envolvidas no desenho e construção do sistema a comentar erros no desenvolvimento de uma especificação ou código do sistema. Já outra fonte de erros, um pouco menos usual, mas também relevante de citar, é o ambiente. Coisas como a presença de radiação, magnetismo, campos elétricos ou poluição podem afetar o hardware e firmware de um sistema, introduzindo defeitos no mesmo.
Sendo assim, se queremos impedir que defeitos de serem inseridos em um sistema, nós precisamos ter meios para evitar que isso aconteça, e se acontecer, ter meios para retificar, ou seja, remove-los do sistema. É aqui que entra o conceito de teste de software, que visa nos auxiliares nesses dois processos. O teste de software que é uma etapa do ciclo de desenvolvimento de software muito importante, porque falhas de software pode causar vários tipos de perdas: em pessoas, fazendo com que as mesmas venham a óbito ou incapacita-las, em empresas, fazendo as mesmas percam dinheiro ou tenham resultados financeiros incorretos, e no meio ambiente, como a liberação de químicos e radiação para a atmosfera por meio de um software com defeito.
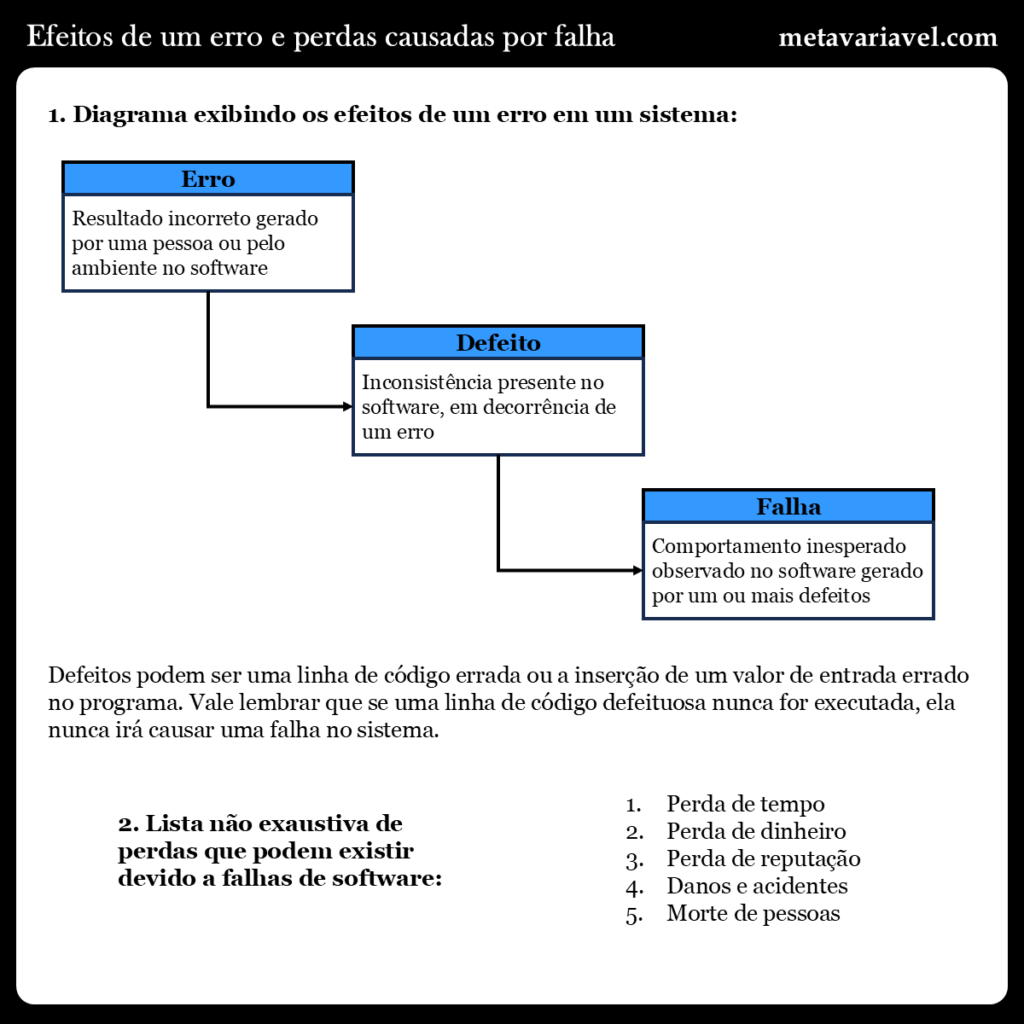
E qual seria a causa dessas perdas? Podemos concluir que ouve a falta de algum teste, ou o tipo errado de teste foi realizado. Podemos pensar que teste é uma tarefa simples, mas não é. O primeiro problema que encontramos é esmagadora quantidade de casos que deveríamos testar, e quanto maior e mais complexo for o sistema, testar todos os casos se tornar inviável, visto que precisaríamos ter um tempo muito grande para realizar todos os testes. Então o primeiro aprendizado é que é impossível fazer testes de maneira exaustiva. E então o que fazemos? É aí que entra o conceito de risco. Nós iremos priorizar a testagem de partes do sistema que apresentarem uma alta probabilidade de falharem, ou melhor, nos lugares onde a falha para nós é importante, e que esta deve ser nula ou minimizada.
Agora para compreender essa questão do risco em contexto, devemos imaginar que existem diferentes empresas com diferentes requisitos de qualidade. Em uma empresa que tem um e-commerce por exemplo, podemos nos dar o luxo de não validar o conteúdo textual do site com afinco, o que pode fazer com que erros ortográficos apareça no site, mas não podemos deixar de testar o fluxo de compras do site, visto que para o e-commerce, se o usuário não consegue fazer uma compra pelo site, estaremos perdendo dinheiro. Agora já em ambientes regulados com risco de vida, como uma empresa responsável pela fabricação do software que controla um centrifugador de urânio, o processo de teste deve ser muito mais exaustivo para ter certeza que não haverá danos ambientais, assim como que a especificação desse software deverá ser mais completa, e com isso mais extensa, do que a da empresa com o e-commerce. Resumindo, a construção de uma casinha de cachorro é diferente da construção de um arranha-céu, e em consequência, o grau de validação, em consequência, teste de cada um será diferente.
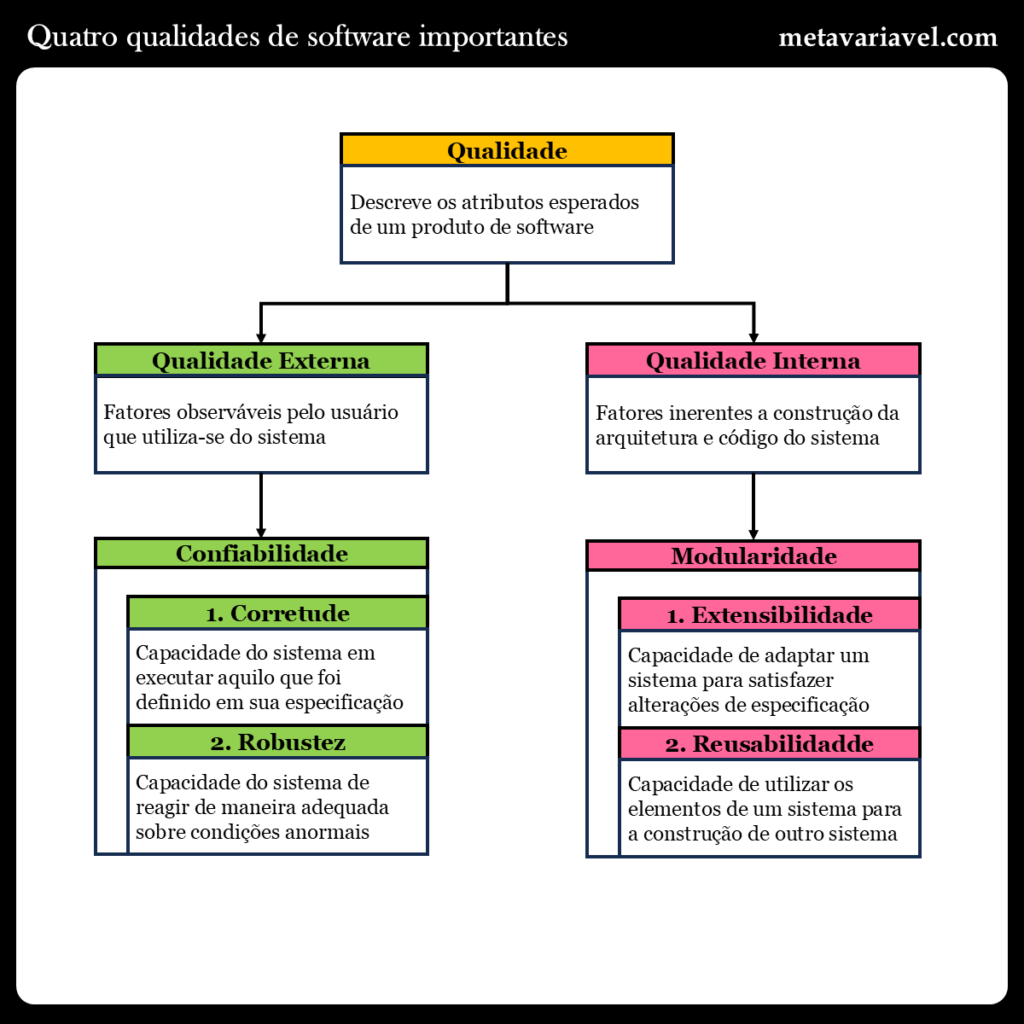
Vamos falar agora de um conceito adjacente, que é o conceito de qualidade de software, que pode ser classificada em dois tipos: o primeiro seria o conceito de qualidade externa, que é a parte do software que está sobre a observação de um usuário. Dentro dessa categoria se encontra qualidades como a velocidade de resposta do sistema, bem como quão fácil é a utilização do sistema para o usuário, o que chamamos de usabilidade. Das qualidades externas, a mais importante de todas é aquela que chamamos de “corretude”, que é a capacidade de um sistema de executar corretamente aquilo que foi definido em sua especificação, ou aquilo que foi acordado que o mesmo deveria executar. Dado uma entrada, o programa irá gerar uma saída, e essa saída é validada de acordo com o valor de entrada inserido no sistema.
Infelizmente a maioria dos sistemas acabam que apresentando somente essa primeira qualidade externa, deixando de lado qualquer outro tipo de qualidade externa ou interna. Visando complementar essa qualidade, a segunda qualidade externa mais importante será a “robustez” de um sistema, que é a habilidade de um sistema de reagir de maneira adequada quando o mesmo passa a trabalhar em condições anormais. Essa segunda qualidade então procurar capturar as coisas que estão fora da especificação, contudo por ela ser mais difusa, ela acaba sendo mais difícil de ser testada, por ela ser menos precisa que a qualidade de corretude. E para se referir as duas qualidades externas juntas, podemos utilizar o termo “confiabilidade”.
Em termos de qualidade interna, podemos destacar duas qualidades: o primeiro seria “extensibilidade” que seria a facilidade de adaptar o software para atingir a mudanças em sua especificação. Essa qualidade está relacionada diretamente com o tamanho do software e número de contribuintes, quanto mais linhas de código o software tiver ou mais pessoas envolvidas no projeto do software, mais esse critério de qualidade se torna importante, para evitar dois problemas: o primeiro que seria a “morte pela complexidade”, onde se torna difícil fazer alterações pelo tamanho do software, e o segundo o “fator ônibus”, onde se uma pessoa for atropelada por um ônibus, as outras pessoas conseguiram manter o projeto e o software funcionando? São essas questões que fazem surgir princípios para solucionar esses dois problemas apresentados.
Então para contornar a complexidade gerada pelo tamanho de um software, devemos procurar desenvolver arquiteturas de software que sejam fáceis de se adaptar a mudanças. Isso significa que devemos priorizar designs que valorizem a simplicidade. É muito melhor uma solução simples para um problema complexo, do que uma solução complexa para um problema complexo. E a segunda solução, seria a de descentralização do software, onde devemos procurar produzir módulos que sejam autômatos um do outro, de modo que uma alteração de um módulo incorra em uma pequena mudança ou nenhuma mudança nos outros módulos do sistema. Devemos evitar o problema de “reação em cadeia” onde uma alteração implica alterar em muitas partes do sistema simultaneamente.
A segunda qualidade interna seria a “reusabilidade”, que é a ideia de utilizar elementos de software que foram utilizados em um sistema para construção de outros sistemas. Isso pode ser atingido através da extração de “pontos em comum” que se apresentam no código dos sistemas, de modo que possamos extrair essas semelhanças em um único lugar, e reutilizar esse código igual para um conjunto de sistemas. Um exemplo prático disso seria a utilização de funções genéricas, padrões de projetos, do inglês “design patterns”, bem como a utilização de bibliotecas e frameworks que encapsulam soluções encontradas para os problemas que estamos tentando resolver no novo sistema, bastante apenas fazer modificações pontuais para adequar a solução genérica para resolver o nosso problema. E para se referir a essas duas qualidades internas apresentadas juntas, pode-se utilizar do termo “modularidade”.
Voltando a questão de teste de software, outra conclusão que devemos observar é que a prática de testes não irá mostrar que um software não apresenta erros, mas sim que testes apenas mostram se um ou mais defeitos existem ou não. Outra conclusão é que devemos procurar executar testes o mais cedo possível no ciclo de desenvolvimento de testes, visto que o custo para corrigir um requisito de software é muito mais barato do que corrigir um bug em um software que está rodando em produção. Também podemos aplicar o princípio de Pareto, onde 80% dos bugs de software provavelmente irá estar concentrado em 20% dos módulos do sistema. E conforme vamos testando o software, com o mesmo conjunto de testes, e corrigindo os defeitos que fomos encontrando, cada vez menos informações este conjunto de testes irá nos fornece, pois os erros envolvidos com os testes tenderam a ser resolvidos, com isso, devemos de tempo e tempo revisar o conjunto de testes, que é o que chamamos de paradoxo da pesticida.
No próximo artigo sobre esse assunto irei mostras as diferentes técnicas de testes de software que existem e como fazer para utiliza-las para conseguir testar um sistema de software.


