Neste artigo iremos ver o que é o conceito de um sistema legado e código legado, os tipos de legado que existem, e sobre o que podemos fazer a respeito. Vamos começar primeiro com o significado do termo "legado". Pelo verbete do dicionário Michaelis podemos ver escrito a definição que legado é "aquilo que se passa de uma geração a outras, que se transmite à posterioridade". Essa definição inicial então nos ajuda entender um pouco o que seria um sistema legado, que seria um sistema que passaria de uma geração para outra, e por geração, estamos falando não somente de geração de programadores, mas também geração de "ideias" de como desenvolver software, como métodos e técnicas, bem como as tecnologias que são utilizadas para tal.
Nesse sentido, a ideia de sistema legado está relacionada a um sistema que foi escrito em uma "geração antiga" e se perpetuou para uma "nova geração", mas que não sofreu alterações para se adequar a nova geração. E não somente isso, temos também o conceito de "posteridade", ou seja, esse sistema, pela sua relevância, continua a existir na nova geração, isto é, ele apresenta uma importância para a instituição que é detentora desse sistema, caso contrário, o sistema teria sido deixado de ser utilizado, e o seu código seria então descartado.
Essa é uma boa pequena introdução, mas não podemos nos conter somente na definição do dicionário, com isso, o termo "legado" também está relacionado a ideia de um código que seja "difícil de modificar", no sentido que, ao modificar esse código, corremos o risco de introduzir novos comportamentos indesejados no sistema, o que chamamos corriqueiramente de "bugs". O legado também pode ser utilizado para se referir a um código em que não houve "cuidado" para manter o mesmo coeso, no sentido que a cada nova alteração no código, não foi feito uma verificação se poderia existir uma refatoração do código existente, isso é, alterar a estrutura do código atual sem alterar o comportamento do mesmo, para uma nova forma que fosse mais fácil de dar manutenção.
Também podemos definir legado como um código em que poucas pessoas sejam capazes de compreender o que foi escrito, devido ao uso de técnicas ou tecnologias que não são mais utilizadas pelo mercado. Por esse motivo, sistemas legados tendem a ter uma maior probabilidade de falhas de segurança, problemas de incompatibilidade com novas tecnologias, e perda de dados, porque o mercado se moveu para uma direção, e pode não existir uma maneira trivial de fazer a atualização do código atual para os novos padrões.
Quando refatorar ou reescrever um sistema legado
Agora que temos alguma ideia do que seria um sistema legado, nos podemos nos perguntar, se vale a pena fazer a transformação do sistema legado para um sistema não-legado. É aqui que entra um grande debate, pois existem pessoas que irão ser favoráveis em continuar com o sistema legado e outras pessoas que irão preferir atualizar o sistema. Mas pensando de maneira lógica, quando é que deveríamos fazer a mudanças? Pois bem, não existe uma receita de bolo, mas existe sim algumas regras práticas que podemos seguir para avaliar se compensa fazer esse processo. E para isso nós precisamos ser capazes de medir e avaliar o custo da "mudança".
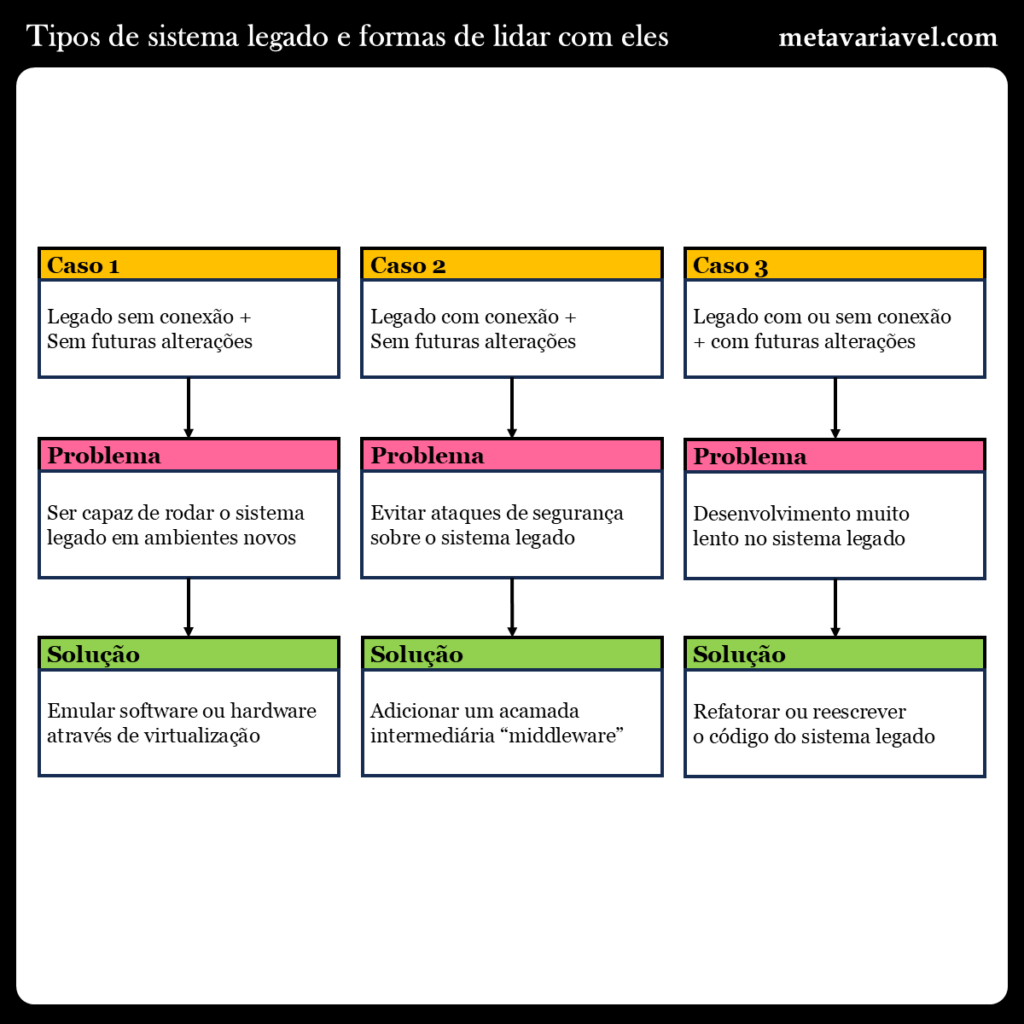
Às vezes, pode ser que o sistema legado é um sistema isolado que não se comunica com outros sistemas, nesse caso, é totalmente plausível não fazer a transformação desse sistema porque corremos o risco de não conseguir recriar o sistema por completo utilizando as novas práticas e tecnologias. Nessa situação, o melhor a ser fazer é utilizar alguma forma de "emulação", seja de hardware ou software, que permita que possamos continuar rodando o sistema. Um exemplo disso seria a utilização virtualização, como máquinas virtuais (VMs), que permitem rodar sistemas operacionais antigos, dentro de sistemas operacionais novos. Com isso removemos o risco de perder um sistema porque o mesmo deixou de ser suportado pelo fabricante.
Contudo é preciso ficar atento as outros fatores, como segurança. Se o sistema em questão apresenta conexão com outros sistemas, ou conexão com a internet, esse sistema corre o risco de sofrer ataques, visto que o mesmo não irá receber atualizações de segurança pelo fim de suporte ao mesmo. Nesse caso, podemos pensar em uma maneira de ter retrocompatibilidade, também chamado de compatibilidade reversa, com o sistema antigo, seja através de uma camada adicional de software ou hardware, que irá ficar entre o sistema antigo e os sistemas novos, a esse sistema intermediário damos o nome de "middleware", e ele será responsável por fazer a integração entre os dois sistemas.
Se o sistema em questão está em constante evolução, e precisa ser modificado para atender a novas regras de negócio, então nesse caso a transformação do sistema para utilizar novas técnicas e tecnologias faz sentido. Isso acontece porque o custo que se tem para trabalhar com o legado, seja em termos de técnicas, tecnologias, funcionários capacitados, acaba sendo mais custoso, do que se o sistema estivesse usando as novas abordagens. Exatamente quando acontece esse ponto de virada, o que chamamos de ponto de quebra, que vem do inglês "breakeven", varia pra cada contexto e sistema, mas para ser capaz de fazer esse cálculo devemos ser capazes de avaliar quantitativamente e qualitativamente os benefícios e malefícios de ser continuar no legado e de migrar para a nova solução.
Existe também duas técnicas para lidar com sistema legado. A primeira delas é, que já foi citada, é a refatoração, onde iremos reescrever o código interno do sistema, contudo o comportamento do sistema, ou seja, como ele faz a conversão das entradas para saídas, deve continuar o mesmo. Essa técnica pode ser empregada tanto em termos a nível de código, como em funções e métodos, até a sistemas e os módulos que o compõem. Quando não é possível garantir o comportamento do sistema, então temos o caso de uma reescrita, que é quando o sistema passa a apresentar um comportamento diferente do comportamento original, mas sem que esse novo comportamento seja uma "bug", mas sim uma mudança de requisito, ou melhoria na qualidade do sistema.
Como fazer modificações em um sistema sem causar "bugs"
Com isso podemos observar que grande parte do esforço com relação a código legado está na "preservação de comportamento" do sistema. Isso porque, como vimos, por ser tratar de um código feito em "outra geração", as novas gerações se sentem desconfortáveis em fazer modificações no sistema, com medo de que ao adicionar novas funcionalidades, seja também inserido novos comportamento indesejados ou a quebra de comportamento existentes. Então a pergunta passa a ser, como podemos ter certeza que estamos fazendo as alterações corretas, que irão fazer aquilo que desejamos, sem quebrar a parte que queremos manter funcionando? É nesse ponto que o conceito de teste de software se relaciona com sistema legados. Para garantir que a corretude e robustez ao fazer alterações no sistema nós precisamos testar o sistema, seja por meio de métodos manuais ou automatizados.
Um sistema computacional pode ser abstraído naquilo que chamamos de sistema de "caixa-preta", que é composto por três componentes básicos: os valores de entrada, o algoritmo, que é representado pela caixa, que recebe os valores de entrada, e transformas os valores em uma ou mais saídas. Para ser capaz de avaliar o comportamento da caixa, podemos apenas observar as entradas e que saídas são geradas por elas. O processo de teste então envolve em verificar se dado as entradas, as saídas estão sendo geradas conforme o esperado. Porém o primeiro grande problema que temos é que muitas vezes, não é conhecido quais são as entradas do sistema, e muito menos que saídas ele apresenta. Então um primeiro passo para compreender o funcionamento de um sistema é fazer a coleta do mapeamento entre entradas e saídas do mesmo.
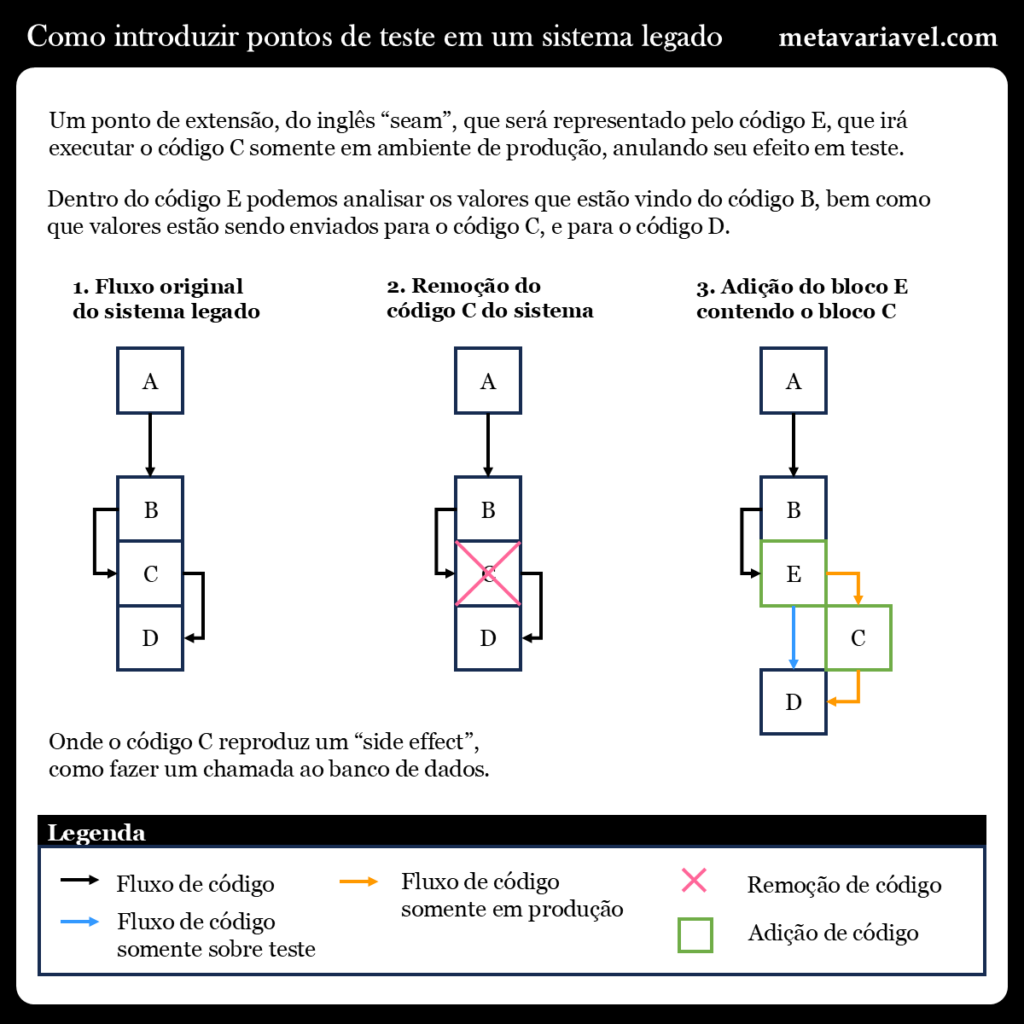
Um sistema é composto por subsistemas, novamente podemos usar a abstração da caixa-preta, onde um sistema é composto por vários módulos, até chegar ao nível de variáveis e funções, na programação procedural, ou a objetos com seus atributos e métodos, em programação orientada a objetos. O segundo grande problema é que, para testar os pedaços interno do sistema, esse pedaço em questão é dependente de outra parte do sistema, o que chamamos de "dependência". Um exemplo seria um código que não está segregado em pequenos pedaços, e dentro dele é feito mais de uma coisa, mas não somente isso, esse pedaço de código para executar pode precisar de recursos externos, como acesso ao banco de dados, pior ainda se o código acessar um banco de dados específico, como o banco de dados de produção. Nesse caso, o primeiro passo para conseguir testar o sistema, é ter um ambiente de teste, onde podemos simular o envio de dados de entrada, e observar os dados de saída.
A maneira que fazemos isso é através da introdução de pontos de extensão, ou em inglês, o que chamamos de "seam", onde imaginamos o código como uma grande malha de retalhos, onde iremos introduzir pontos de costura, também chamado de extensão. O ponto de extensão é um lugar no código onde podemos alterar o comportamento do mesmo sem fazer a alteração do código naquele lugar. Parece confuso, mas a ideia é simples, imagine que você tem um código A que dentro dele executa o código B, C e D, mas você não quer executar o código C durante o seu teste, porque o mesmo irá chamar o banco de dados para salvar as alterações, para anular esse efeito, você deve inserir um código E no lugar de C, que quando o sistema está no modo de "teste" não irá executar C mas em produção C será executado.
Com isso, os pontos de extensão nos permitem avaliar o estado do sistema em teste, sem alterar o código em produção. Podemos então testar o sistema nesse ponto de extensão, através da aplicação de teste unitário, usar um debugador para alterar os valores de entrada que entram naquele ponto do código, e ver que saída é gerada, ou manualmente podemos inserir os valores no sistema, e colocar um código para armazenar os valores de entrada e saída naquele trecho de código, descobrindo assim o comportamento do sistema naquele pedaço de código em que o ponto de extensão foi feito.
No próximo artigo sobre esse assunto irei mostrar exemplos práticos com código de como podemos implementar os pontos de extensão para avaliar o estado de um sistema legado.


